关于拼多多后台详细数据的加密分析
之前在获取店铺后台数据的时候就遇到了获取商品访客,成交等数据时获取到的数据全是小方块,如下图
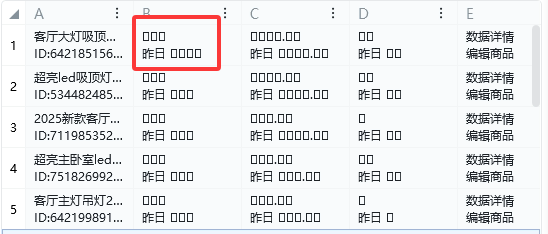
最开始我发现这个小方块和每个数字是对应的,想看看是不是可以直接写一个固定的映射,结果发现每次刷新或者重新打开都是不相同的映射,很明显得自己去做字典了。
这样的数据并不是我们需要的,之前我想了个办法,通过ocr挨个去识别字符,先找到一个特征组,也就是找到每个小方格对应的数字是什么,最后的效果如下
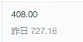

找到这个对应关系就可以再去抓取数据,然后替换数据就可以了,这些内容不在这次的探讨里面,也很简单,原本以为这样就可以了,但是后面会发现有时候数字很短的时候,比如个位数的时候,截图下来很小,识别并不是很准确,然后我又做了一个对碰组,如果后面识别到的数据和我已经确定好的对应关系不相同,就把这个特征组里面的数据去除,重新再匹配,直到取到完整的映射表,这样就可以解决问题了。
在这之后...也就是前面几天,发现要获取一个新数据,用之前哪个效率太慢了,取特征组的时间要比较长,所以又改进了一下流程,我们打开开发者工具就能发现,这是一个典型的字体加密,也就是它后台返回的数据和这次给到的字体有自己的映射关系
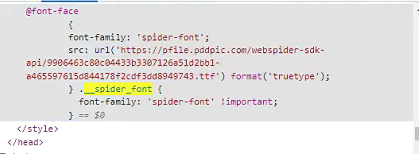
通过打开这个字体文件,我们发现这里面就包含了全部的数字和小数点


但是现在有个问题,获取多几次发现这个数字顺序并不是固定的,而且unicode编码也不相同,那么这里我们就还是要通过其它方式去找到对应的关系
我最后选择了用python去把数字都用unicode编码去输出为图片,这个图片的识别准确率基本上是百分之百,这里贴一下python解析的代码
from PIL import Image, ImageDraw, ImageFont
from fontTools.ttLib import TTFont
import os
# --- 配置 ---
FONT_PATH = r"D:\下载\pddzt2.ttf" # 替换为您的字体文件实际路径
OUTPUT_DIR = r"D:\下载\字体图" # 输出图片的文件夹
CHARACTER_SIZE = 128 # 图片的尺寸 (宽度和高度)
TEXT_COLOR = (0, 0, 0) # 文字颜色 (黑色)
BG_COLOR = (255, 255, 255) # 背景颜色 (白色)
TEXT_SCALE = 0.8 # 文字相对于图片尺寸的缩放比例 (避免文字顶到边缘)
# ------------
def get_font_glyphs_with_unicode(font_path):
"""
使用 fontTools 读取字体文件,获取所有具有 Unicode 编码的字形及其编码。
返回一个字典: {unicode_code_point: glyph_name}
"""
try:
font = TTFont(font_path)
cmap = font.getBestCmap() # 获取最佳字符映射表
font.close()
return cmap
except Exception as e:
print(f"读取字体文件失败: {e}")
return {}
def create_image_for_char(char_code, font_path, output_dir, size, text_color, bg_color, scale):
"""
为单个字符(由其 Unicode 编码指定)创建图片。
"""
# 创建一个空白图片
img = Image.new('RGB', (size, size), bg_color)
draw = ImageDraw.Draw(img)
try:
# 尝试使用 PIL 直接加载字体 (Pillow 通常能处理大多数 TTF/OTF)
# 注意: PIL 的 ImageFont 不能直接按 Unicode 编码点选择字形,但可以显示对应字符
# 我们需要先将编码点转换为字符
try:
char = chr(char_code) # 将整数编码转换为 Python 字符
except ValueError:
print(f" 编码 {hex(char_code)} 无法转换为有效字符。")
return False
# 加载字体 (指定大小,size 是图片大小,文字大小需要按比例)
font_size = int(size * scale)
try:
font = ImageFont.truetype(font_path, font_size)
except OSError:
print(f" 无法加载字体文件: {font_path}")
return False
# 计算文字在图片中的位置 (居中)
# bbox 返回 (left, top, right, bottom)
bbox = draw.textbbox((0, 0), char, font=font)
text_width = bbox[2] - bbox[0]
text_height = bbox[3] - bbox[1]
x = (size - text_width) // 2 - bbox[0] # 减去 bbox[0] 是为了处理字体的偏移
y = (size - text_height) // 2 - bbox[1]
# 在图片上绘制字符
draw.text((x, y), char, fill=text_color, font=font)
# 构建输出文件名 (使用十六进制编码)
filename = f"U+{char_code:04X}_{char}.png" # 例如 U+002E_..png
# 替换文件名中可能的非法字符 (如 /, \, :, *, ?, ", <, >, |)
filename = "".join(c if c.isalnum() or c in ('_', '-', '.') else '_' for c in filename)
output_path = os.path.join(output_dir, filename)
# 保存图片
img.save(output_path, format='PNG')
print(f" 已保存: {output_path}")
return True
except Exception as e:
print(f" 渲染字符 {hex(char_code)} 时出错: {e}")
return False
def main():
# 创建输出目录
os.makedirs(OUTPUT_DIR, exist_ok=True)
# 获取字体中的字符映射
print("正在读取字体文件...")
cmap = get_font_glyphs_with_unicode(FONT_PATH)
if not cmap:
return
print(f"找到 {len(cmap)} 个映射的字符。")
print("正在生成图片...")
# 遍历 cmap 中的每个 Unicode 编码
for code_point, glyph_name in cmap.items():
print(f"处理编码: U+{code_point:04X} (字形: {glyph_name})")
success = create_image_for_char(
code_point, FONT_PATH, OUTPUT_DIR,
CHARACTER_SIZE, TEXT_COLOR, BG_COLOR, TEXT_SCALE
)
if not success:
print(f" 失败: U+{code_point:04X}")
print(f"完成!图片已保存在 '{OUTPUT_DIR}' 文件夹中。")
if __name__ == "__main__":
main()这样我们就得到一个完整的图片和unicode对应
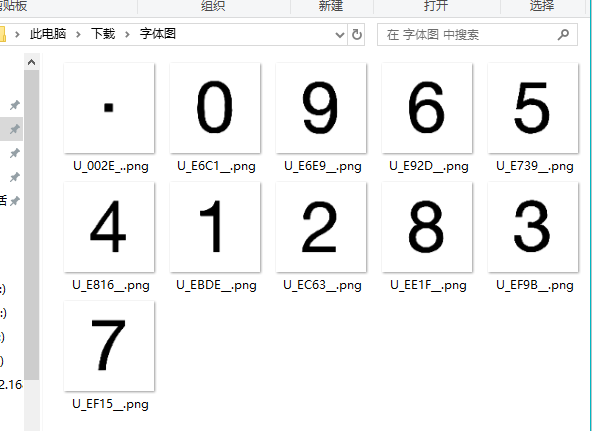
然后我们挨个识别做成映射表,然后再替换就行了,效果如下

那么久完成了我们需要的字典解密,至于如何获取到字体文件,可以直接监听接口,或者获取页面资源等都可以,然后要注意的是,抓取的后台数据需要对字符进行unicode编码,不能直接用字符,因为现在是用unicode编码进行做的映射表,有疑问欢迎留言,此教程仅供参考学习,切勿去非法爬取数据,转载请注明出处,luckxi.cn